 |
Streaming data is a big deal in big data these days. As more and more businesses seek to tame the massive unbounded data sets that pervade our world, streaming systems have finally reached a level of maturity sufficient for mainstream adoption. With this practical guide, data engineers, data scientists, and developers will learn how to work with streaming data in a conceptual and platform-agnostic way. Expanded from Tyler Akidau’s popular blog posts Streaming 101 and Streaming 102, this book takes you from an introductory level to a nuanced understanding of the what, where, when, and how of processing real-time data streams. You’ll also dive deep into watermarks and exactly-once processing with coauthors Slava Chernyak and Reuven Lax. |
|
“If you care about the correctness of your streaming and batch processing jobs, this book is a must-read. It provides the most clearthinking and logical discussion of the topic that I have seen, and its ideas are brilliantly explained.”
|

10 chapters of streamy goodness
| 1. Streaming 101 | 2. The What, Where, When, and How of Data Processing |
|---|---|
| Why streaming is awesome, death to Lambda Architecture, data processing patterns. | The basics, explained in prose, animation, limmerick, and interpretive dance.* |
| 3. Watermarks | 4. Advanced Windowing |
| Progress and completeness in unbounded data sets, how watermarks are established and propagated, real-world examples. | Practical considerations for going beyond the basics: processing-time windows, sessions, and the importance of custom windowing. |
| 5. Exactly-Once and Side Effects | 6. Streams and Tables |
| The illusionary art of creating perfection out of imperfection; the mythical beasts known as idempotence and determinism; how Apache Flink, Apache Spark, and Google Cloud Dataflow work their magic. | The basis for life, the universe, and everything, assuming a data-processingly skewed definition of the above, or: that feeling when you realize everything you do was invented by the database community decades ago. |
| 7. The Practicalities of Persistent State | 8. Streaming SQL |
| For those "functional programming be damned, just give me a Turing machine" kinds of days. | Contorting relational algebra for fun and profit. Also, time-varying relations will change your life. |
| 9. Streaming Joins | 10. The Evolution of Large-Scale Data Processing |
| A brief moment of panic upon realizing that all joins are streaming at the core, followed by a prolonged sense of relief upon realizing it makes them all the easier to understand. | An opinionated history of stream processing in the MapReduce lineage of systems, with a healthy dose of source material citations for drawing your own conclusions. |
*Not all formats include all interpretations.
Illustrative animated figures
Many of the concepts presented in the book are accompanied by detailed animated figures that bring the ideas to life. The Safari Books Online version includes the animations inline, while all other versions (PDF, EPUB, print) include a montage of key frames within the animation, plus a link to the animated version on this website. You can also browse the complete list of figures here.
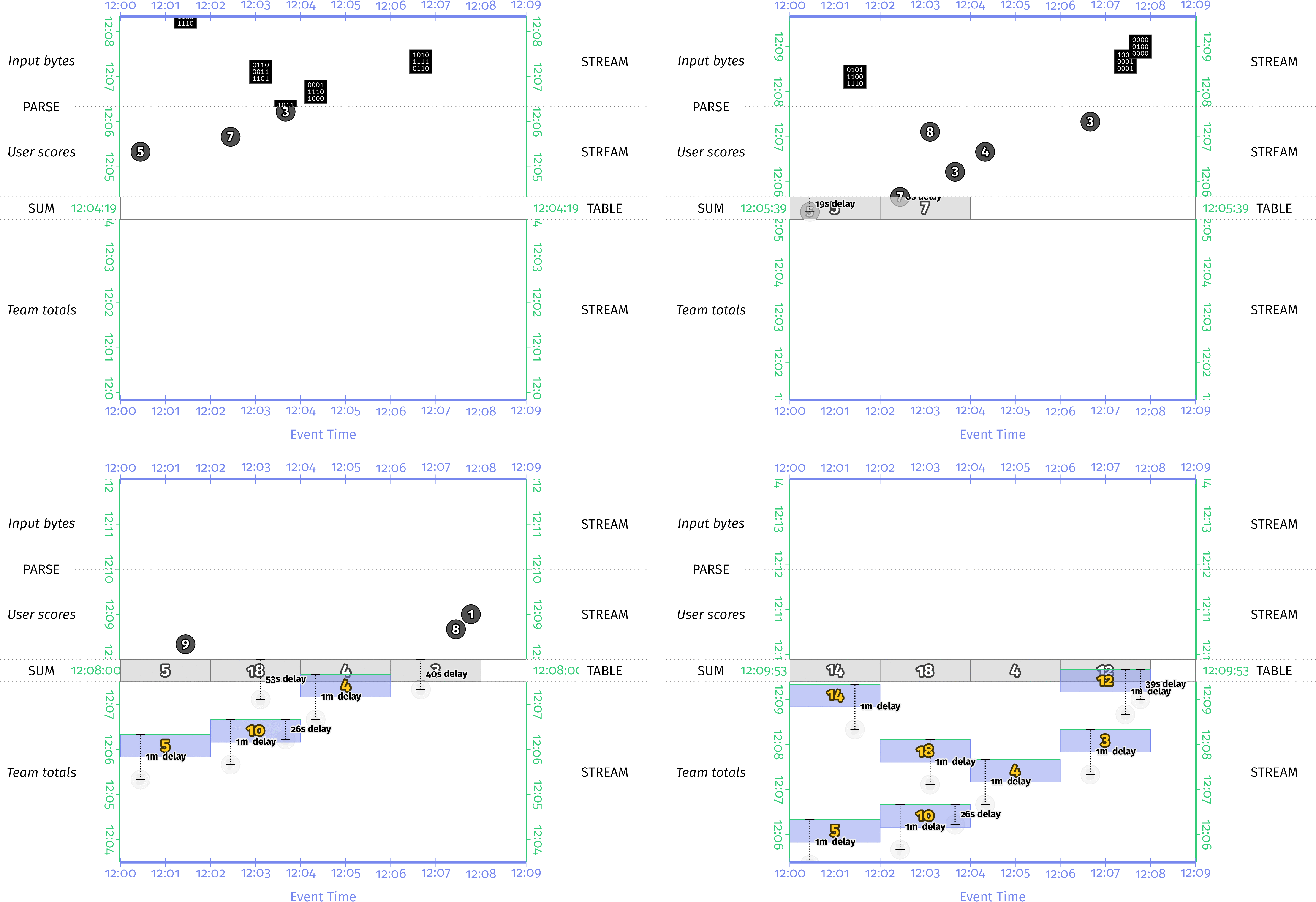 |
|
| Figure 8-12: Montage | Figure 8-12: Animation |
Informative code snippets
Although primarily focused on teaching concepts, the book is accompanied by a suite of simple code snippets illustrating those concepts using Apache Beam. Most of the example pipelines in Streaming Systems have Java implementations as well as corresponding unit tests that highlight the results of executing those pipelines over the sample datasets from the book. Code snippets are all available at github.com/takidau/streamingbook.
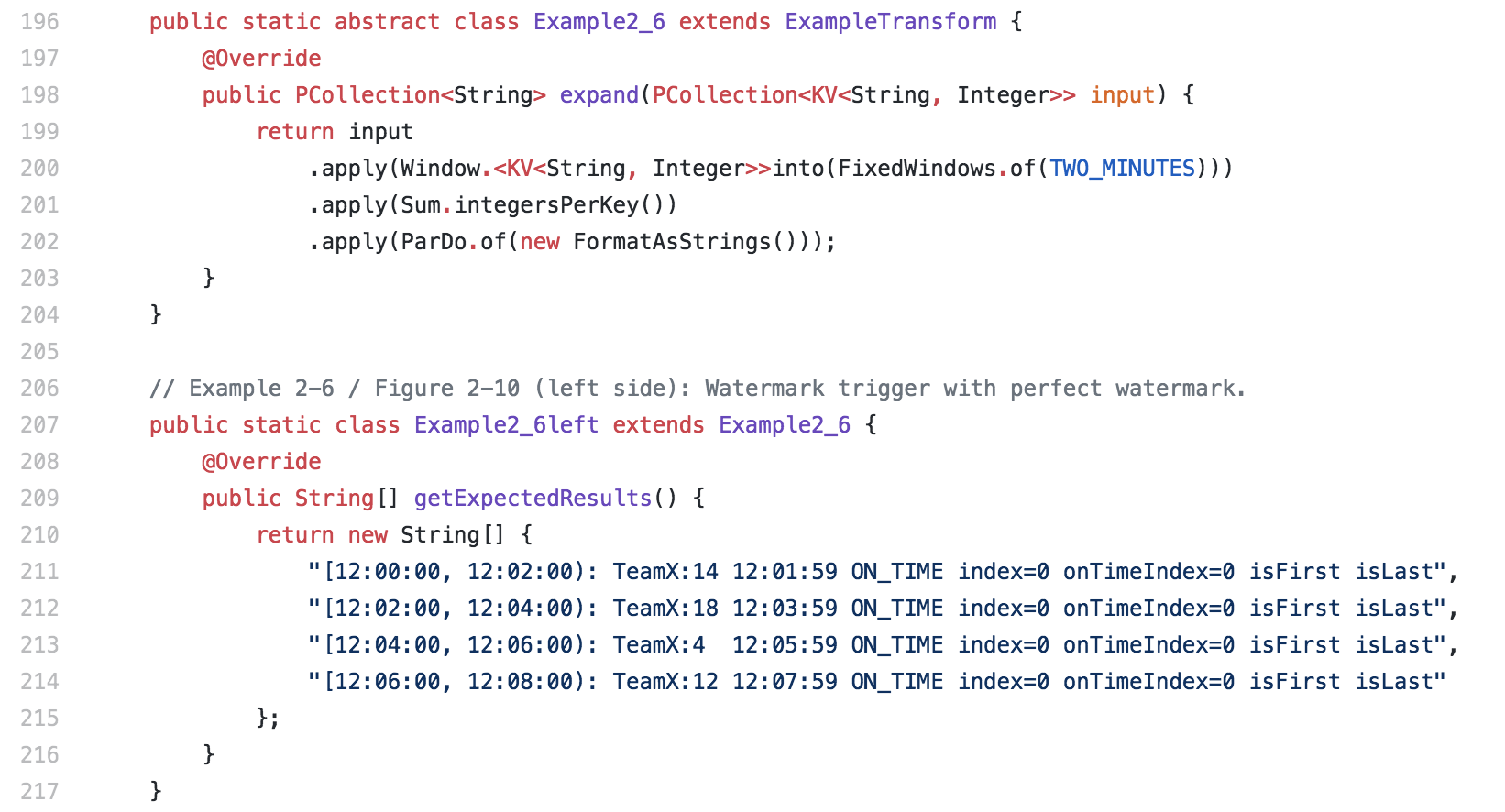
Full source code for all of the animated figures in the book is also provided at github.com/takidau/animations.
About the authors
|
Tyler Akidau @takidau 
|
Slava Chernyak
|
Reuven Lax @reuvenlax 
|
|---|---|---|
|
Tyler Akidau is a principal software engineer at Snowflake, driving the effort to build a new stream processing engine within the Snowflake Data Cloud. Prior to Snowflake, he was a senior staff software engineer at Google, where he was the technical lead for the Data Processing Languages & Systems group, responsible for Google's Apache Beam efforts, Google Cloud Dataflow, and internal data processing tools like Google Flume, MapReduce, and MillWheel. He is also a founding member of the Apache Beam PMC. Though deeply passionate and vocal about the capabilities and importance of stream processing, he is also a firm believer in batch and streaming as two sides of the same coin, with the real endgame for data processing systems the seamless merging between the two. He is the author of the 2015 Dataflow Model paper and the Streaming 101 and Streaming 102 articles on the O’Reilly website. His preferred modes of transportation are bicycle and ski, with his two young daughters trailing close behind. |
Slava Chernyak is a senior software engineer at Google Seattle. Slava spent more than six years working on Google’s internal massive-scale streaming data processing systems and has since become involved with designing and building Windmill, Google Cloud Dataflow's next-generation streaming backend, from the ground up. Slava is passionate about making massive-scale stream processing available and useful to a broader audience. When he is not working on streaming systems, Slava is out enjoying the natural beauty of the Pacific Northwest. |
Reuven Lax is a senior staff software engineer at Google, Seattle, and has spent the past ten years helping to shape Google's data processing and analysis strategy. For much of that time he has focused on Google's low-latency, streaming data processing efforts, first as a long-time member and lead of the MillWheel team, and more recently founding and leading the team responsible for Windmill, the next-generation stream processing engine powering Google Cloud Dataflow. He is also a Beam PMC member. He's very excited to bring Google's data processing experience to the world at large and proud to have been a part of publishing both the MillWheel paper in 2013 and the Dataflow Model paper in 2015. When not at work, Reuven enjoys swing dancing, rock climbing, and exploring new parts of the world. |